-
(2) 자연어처리_데이터전처리자연어처리 2023. 7. 11. 02:26728x90
1. 코퍼스(Corpus)
- 사전적인 의미는 "말뭉치", "대량의 텍스트 데이터"를 말함
- 자연어처리 연구나 애플리케이션 활용을 염두에 두고 수집된 텍스트 데이터셋을 의미
2. 토큰화(Tokenization)
- 전처리 과정에는 토큰화, 정제, 정규화 작업 등이 있음
- 토큰화는 원시 데이터를 가져와 유용한 데이터 문자열로 변환하는 간단한 프로세스
- 사이버 보안, NFT 생성에 사용되는 것으로 유명, 자연어 프로세스의 중요한 부분을 차지함
- 토큰의 단위는 자연어 내에서 의미를 가지는 최소 단위로 정의
- 단락과 문장을 보다 쉽게 의미를 할당할 수 있는 더 작은 단위로 분할하는데 사용
토큰화 작업은 주어진 코퍼스내 자연어 문장들을 토큰이라 불리는 최소 단위로 나누는 작업
2-2. 토큰화 방법
- 문장 토큰화: 토큰의 기준을 문장으로 하는 토큰화 방법
- 문장의 끝에 오는 문장 부호를 기준으로 코퍼스를 잘라냄(. 또는 ! 또는 ?)
- 예외) 제 이메일 주소는 asd@asd.com 입니다.
- 단어 토큰화: 토큰의 기준을 단어로 하는 토큰화
- 보편적으로 구분기호를 가지고 텍스트를 나누게 되며, 기본적으로 공백을 구분자로 사용
- 한국어의 경우 교착어이기 때문에 공백으로 단어 토큰화를 하면 성능이 좋지 않음
- 새로운 단어가 추가될수록 단어 사전의 크기가 계속 증가
- OOV(Out of Vocabulary) 문제
- 문자 토큰화: 토큰의 기준을 문자로 하는 토큰화 방법
- 단어 토큰화의 한계점들을 해결하기 위한 방법
- 영어는 26개의 알파벳에 따라 분리, 한국어는 자음 19개와 모음 21개의 글자에 따라 분리
- 단어 사전은 작지만 모델의 예측 시간에 문제가 생길 수 있음
- 서브워드 토큰화: 토큰의 기준을 서브단어로 하는 토큰화 방법
- 단어 토큰화와 문자 토큰화의 한계정을 해결하기 위한 방법
- 문자 토큰화의 확장된 버전으로 토큰의 단위를 n개의 문자로 정의하고, 해당 기준에 따라 텍스트를 분절하는 방법
- 형태소 분절 기반의 서브워드 토큰화로 확장될 수 있어 한국어에서도 좋은 성능을 가짐
- 서브 워드를 만드는 알고리즘 중에서 가장 유명한 것이 BPE
3. 서브워드 토큰화
3-1. 서브워드(subword)
- 단어보다 더 작은 의미의 단위
- 예 Birthday = birth + day, 아침밥 = 아침 + 밥
- 단어를 여러 서브워드로 분리해서 단어 사전을 구축하겠다는 토큰화 방법
- 신조어에서 주로 발생하는 OOV 문제를 완화
3-2. BPE(Byte Pair Encoding)
- 코퍼스 내 단어의 등장 빈도에 따라 서브워드를 구축하는데 사용
- 2016년 Neural Machine Translation of Rare Words with Subword Units 논문에서 처음 제안
- 글자 단위에서 점진적으로 서브워드 집합을 만들어내는 Bottom-up 방식의 접근 방식으로 자연어 코퍼스에 있는 모든 단어들을 글자 단위로 분리한 뒤에, 등장 빈도에 따라 글자들을 서브워드로 통합하는 방식
3-3. WordPiece Tokenizer
- 구글이 2016년도 Google`s Neural Mashine Translation System Bridging the Gap between Human and Machine Translation 논문에 처음 공개한 BPE의 변형 알고리즘
- 병합할 두 문자가 있을 때, 각각의 문자가 따로 있을 때를 더 중요시 여기는지, 병합되었을 때를 더 중요시 여기는지에 차이점을 둠
- GPT모델과 같은 생성 모델의 경우에는 BPE 알고리즘을 사용
- BERT, ELECTRA와 같은 자연어 이해 모델에서는 WordPiece Tokenizer를 주로 사용
4. 정제(Cleaning)
- 토큰화 작업에 방해가 되는 부분들을 필터링 하거나 토큰화 작업 이후에도 여전히 남아있는 노이즈들을 제거하기 위해 지속적으로 이뤄지는 전처리 과정
- 어떤 특성이 노이즈인지 판단하거나, 모든 노이즈를 완벽하게 제거하는 것은 어렵기 때문의 일종의 합의점을 찾아야함
4-1. 정제 작업의 종류
- 불용어(Stopword) 처리
- NLTK 라이브러리에서는 자주 사용되는 단어들을 불용어로 정의
- 불용어의 정의는 가변적이기 때문에 추가하고 싶은 불용어가 있다면 직접 정의할 수 있음
- 보편적으로 선택할 수 있는 한국어 불용어 리스트(https://www.ranks.nl/stopwords/korean)
- 불필요한 태그 및 특수 문자 제거
- 코퍼스 내 등장 빈도가 적은 단어 제거
- 코퍼스 내 단어들의 빈도를 분석하여 분포를 보고 특정 threshold를 설정한 후, 해당 threshold를 아래의 단어들을 필터링하는 방식으로 정제
4-2. 정제 과정에서 유의해야할 점
- @과 같은 특수 문자는 일반적인 작업에서는 정보량이 적은 토큰일 수 있지만 이메일과 관련한 내용을 판단해야 하는 작업에서는 유용한 토큰으로 사용될 수 있음
자연어처리 작업에서 데이터를 수집한 이후에는 항상 목적에 맞지 않는 노이즈가 있진 않은지 검사하고 발견한 노이즈를 정제하기 위한 노력이 필요
5. 정규화(Normalization)
- 일반적인 머신러닝 작업에서 데이터 정규화는 학습 데이터의 값들이 적당한 범위를 유지하도록 데이터의 범위를 변환하거나 스케일링하는 과정
- 정규화 목표는 모든 데이터가 같은 정도의 스케일로 반영되도록 하는 것
- 자연어 처리 정규화의 핵심은 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어주는 과정
5-1. 정규화 작업이 필요한 이유
- 이상적으로 단어 사전내의 단어 토클들이 모두 중요하게 고려되길 원함
- 자연어의 특성 상 의미가 같은데 표기가 다른 단어들이 있을 수 있고, 의미는 같지만 사용 빈도도가 다른 단어들을 통합할 수 있음
- 의미가 같지만 표기가 다른 단어들을 통합할 수 있다면 통합된 단어의 사용 빈도가 높아질 것이고, 사용 빈도가 낮은 단어들의 중요도가 높아질 수 있음
5-2. 정규화 작업의 종류
- 어간추출, 표제어추출
- 어간 추출: 형태학적 분석을 단순한 비전으로, 정해진 규칙만 보고 단어의 어미를 자르는 어림짐작의 작업
- 표제어 추출: 단어들이 다른 형태를 가지더라고, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단하는 방법
- 대소문자 통합
- 대문자와 소문자가, 구분대어야 하는 경우도 있음
- 예) us (미국), us(우리)
5-3. 정규화 시 유의할 점
- 규칙이 너무 엄격한 정규화 방법은 부작용이 심해 학습에 악영향을 줄 수 있음
- 원본 의미를 최대한 유지하는 것이 학습에 도움이 됨
- 대화에서 사용하는 의미가 비슷한 이모티콘들을 통합하는 정규화 작업
- "ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ" -> "ㅋㅋㅋㅋㅋ"
6. 한국어 데이터 전처리
6-1 한국어의 특성
- 영어는 합성이나 줄임말에 대한 예외처리만 한다면, 띄어쓰기를 기준으로 하는 토큰화 작업으로도 어느 정도의 성능을 보장할 수 있음
- 한국어에는 조사나 어미가 발달되어 있기 때문에 띄어쓰기만으로 단어를 분리하면 의미적인 훼손이 일어날 수 있음
- 띄어쓰기 단위가 되는 단위를 "어절" 이라고 하는데 어절 토큰화와 단어 토큰화가 같지 않기 때문
6-2. 형태소 분석
- 형태서를 비롯하여, 어근/접두사/접미사/품사 등 다양한 언어적 속성의 구조를 파악하는 것을 의미
- 형태소 분석 과정은 한국어 단어에서 형태소를 추출하여 분리하는 작업이며 이후에 필요에 따라 사전 정의된 품사를 해당 단어에 태깅하는 작업을 하기도 함
- 태깅: 형태소의 뜻과 문맥을 고려하여 단어에 품사를 매핑하는 것
6-3. 형태소 분석 방법
- 한국어의 다양한 형태소를 분석하고 분류하기 위해 KoNLPy 패키지에서 분석이름 사용
- KoNLPy 패키지의 다양한 함수를 사용하여 한국어 내 다양한 전처리를 진행
- Mecab: 일본어용 형태소 분석기를 한국어를 사용할 수 있도록 수정
- Okt: 오픈 소스 한국어 분석기. 과거 트위터 형태소 분석기
- Komoran: Shineware에서 개발
- Kkma: 서울대학교 IDS 연구실 개발
- 각 형태소 분석기는 성능과 결과가 다르게 나오기 때문에 사용하고자 하는 필요 용도에 어떤 형태소 분석기가 적절한지를 판단
- 속도를 중시한다면 Mecal을 사용
7. 실습
# 뉴스기사 크롤링 라이브러리 설치! pip install newspaper3kfrom newspaper import Article
article = Article(URL, language = 'ko')article.download()article.parse()
print('title:',article.title)print('content:',article.text) additional_info = ["※ 기자 김사과(apple@apple.com) 취재 반하나(banana@banana.com)","<h2>톰 크루즈가 연기하는 아이언맨 '결사반대'한다는 로다주</h2>","이 기사는 임시 데이터임을 알림니다 … ","Copyrights© Pressian.com","<br> ☞ 이 기사는 문화 섹션으로 분류 했습니다 … </br>","#기사 #문화 #톰크루즈 #반대"]
additional_info = ["※ 기자 김사과(apple@apple.com) 취재 반하나(banana@banana.com)","<h2>톰 크루즈가 연기하는 아이언맨 '결사반대'한다는 로다주</h2>","이 기사는 임시 데이터임을 알림니다 … ","Copyrights© Pressian.com","<br> ☞ 이 기사는 문화 섹션으로 분류 했습니다 … </br>","#기사 #문화 #톰크루즈 #반대"]
context = article.text.split("\n")context += additional_infofor i, text in enumerate(context):print(i,text)
7-1. 불용어 제거
# 불용어 제거하기stopwords = ['이하','바로','☞','※','…']
def delete_stopwords(context):preprocessed_text = []for text in context:text = [w for w in text.split(' ') if w not in stopwords]preprocessed_text.append(' '.join(text))return preprocessed_textprocessed_context = delete_stopwords(context)for i, text in enumerate(processed_context):print(i,text)
7-2. HTML 태그 제거
import redef delete_html_tag(context):preprocessed_text = []for text in context:text = re.sub(r'<[^>]+>\s+(?=<)|<[^>]+>', '', text).strip()if text:preprocessed_text.append(text)return preprocessed_textprocessed_context = delete_html_tag(processed_context)for i, text in enumerate(processed_context):print(i,text)
7-3. 문장 분리
- 학습 데이터를 구성할 때 입력 데이터의 단위를 설정하기 애매해지므로 문장 단위로 모델이 학습하도록 유도하기 위해 문장 분리가 필요
- 한국어 문장 분리기 중 , 가장 성능이 우수한 것으로 알려진 [kss 라이브러리] (https://github.com/hyunwoongko/kss) 를 사용
!pip install kssimport kssdef sectence_seperator(processed_context):splited_context = []
for text in processed_context:text = text.strip()if text:splited_text = kss.split_sentences(text)splited_context.extend(splited_text)
return splited_contextsplited_context = sectence_seperator(processed_context)for i, text in enumerate(processed_context):print(i,text)
7-4. 이메일 제거
def delete_email(context):preprocessed_text = []
for text in context:text = re.sub(r'[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+', '', text).strip()
if text:preprocessed_text.append(text)
return preprocessed_textprocessed_context = delete_email(processed_context)for i, text in enumerate(processed_context):print(i,text)
7-5. 해시태그 제거
def delete_hashtag(context):preprocessed_text = []for text in context:text = re.sub(r'#\S+', '', text).strip()if text:preprocessed_text.append(text)return preprocessed_textprocessed_context = delete_hashtag(processed_context)for i, text in enumerate(processed_context):print(i,text)
7-6. 저작권 관련 테스트 제거
def delete_copyright(context):re_patterns = [r'\<저작권자(\(c\)|©|(C)|(\(C\))).+?\>',r'(Copyrights)|(\(c\))|(\(C\))|©|(C)|']preprocessed_text = []for text in context:for re_pattern in re_patterns:text = re.sub(re_pattern, "", text).strip()if text:preprocessed_text.append(text)return preprocessed_textprocessed_context = delete_copyright(processed_context)for i, text in enumerate(processed_context):print(i,text)
7-7. 반복 횟수가 많은 문자 정규화
!pip install soynlpfrom soynlp.normalizer import *print(repeat_normalize('ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ',num_repeats=2)) print(repeat_normalize('야!!!!!!!!!!!!!!!!!!!!!!!!!! 너!!!!!!!!!!!!!!!!!!!!!!!!!!! 지지지ㅈㅈㅈ 뭐함 ㅡㅡㅡㅡㅡㅡㅡ', num_repeats = 2))
print(repeat_normalize('야!!!!!!!!!!!!!!!!!!!!!!!!!! 너!!!!!!!!!!!!!!!!!!!!!!!!!!! 지지지ㅈㅈㅈ 뭐함 ㅡㅡㅡㅡㅡㅡㅡ', num_repeats = 2))
7-8. 띄어쓰기 보정
!pip install git+https://github.com/haven-jeon/PyKoSpacing.gitfrom pykospacing import Spacing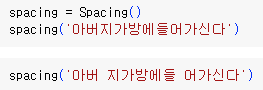
7-9. 중복 문장 정규화
from collections import OrderedDictdef duplicated_sentence_normalizer(context):context = list(OrderedDict.fromkeys(context))return contextnormalized_context = duplicated_sentence_normalizer(processed_context)for i, text in enumerate(normalized_context):print(i,text)
7-10. Cleaning
- 형태소 분석 기반 필터링
- 데이터 후처리

 # 명사(NN), 동사(V), 형용사(J)의 포함 여부에 따라 문장 필터링def morph_filter(context):NN_TAGS = ['NNG', 'NNP', 'NNB', 'NP']V_TAGS = ['VV', 'VA', 'VX', 'VCP', 'VCN', 'XSN', 'XSA', 'XSV']J_TAGS = ['JKS', 'J', 'JO', 'JK', 'JKC', 'JKG', 'JKB', 'JKV', 'JKQ','JX', 'JC', 'JKI', 'JKO', 'JKM', 'ETM']
# 명사(NN), 동사(V), 형용사(J)의 포함 여부에 따라 문장 필터링def morph_filter(context):NN_TAGS = ['NNG', 'NNP', 'NNB', 'NP']V_TAGS = ['VV', 'VA', 'VX', 'VCP', 'VCN', 'XSN', 'XSA', 'XSV']J_TAGS = ['JKS', 'J', 'JO', 'JK', 'JKC', 'JKG', 'JKB', 'JKV', 'JKQ','JX', 'JC', 'JKI', 'JKO', 'JKM', 'ETM']
preprocessed_text = []
for text in context:
morphs = mecab.pos(text, join=False)nn_flag = Falsev_flag = Falsej_flag = False
for morph in morphs:pos_tags = morph[1].split("+")for pos_tag in pos_tags:
if not nn_flag and pos_tag in NN_TAGS:nn_flag = Trueif not v_flag and pos_tag in V_TAGS:v_flag = Trueif not j_flag and pos_tag in J_TAGS:j_flag = True
if nn_flag and v_flag and j_flag:preprocessed_text.append(text)break
return preprocessed_textpost_precessed_text = morph_filter(normalized_context)for i, text in enumerate(post_precessed_text):print(i,text)
7-11. 문장 길이 기반 필터링
def min_max_filter(min_len, max_len, context):te = []for text in context:if len(text) >= 20 and len(text) <= 60:te.append(text)return tepost_precessed_context = min_max_filter(20,60, post_precessed_text)post_precessed_context
7-12. 토큰화
from tensorflow.keras.preprocessing.text import Tokenizertokenizer = Tokenizer()tokenizer.fit_on_texts(post_precessed_context)word2idx = tokenizer.word_index# word2idxidx2word = {value : key for key,value in word2idx.items()}# idx2wordencoded = tokenizer.texts_to_sequences(post_precessed_context)encoded vocab_size = len(word2idx) + 1print(f'단어 사전의 크기: {vocab_size}')
vocab_size = len(word2idx) + 1print(f'단어 사전의 크기: {vocab_size}')
'자연어처리' 카테고리의 다른 글
(6) 자연어처리_Seq2Seq (0) 2023.07.30 (5) 자연어처리_ 워드 임베딩 시각화 (0) 2023.07.30 (4) 자연어처리_워드임베딩 (0) 2023.07.30 (3) 자연어처리_임베딩 (0) 2023.07.11 (1) 자연어 처리 개요 (2) 2023.07.10