
자연어처리
(15) 자연어처리_KLUE
빠스무
2023. 8. 2. 00:46
728x90
1. KLUE(한국어 자연어 이해 평가 데이터셋)
- 한국어 언어모델의 공정한 평가를 위한 목적으로 8개의 종류가 포함된 공개 데이터셋
- 뉴스 헤드라인 분류
- 문장 유사도 비교
- 자연어 추론
- 개체명 인식
- 관계 추출
- 형태소 및 의존 구문 분석
- 기계 독해 이해
- 대화 상태 추적
- 한국어 언어 모델의 공정한 성능 비교를 위해 평가 시스템을 구축
2. 학습 데이터
- 광범위한 주제와 다양한 스타일을 포괄하기 위해 다양한 출처에서 공개적으로 사용 가능한 한국어 말뭉치를 수집
- 약 62GB 크기의 최종 사전 학습 코퍼스 구축
- MODU: 국립국어원에서 배포하는 한국어 말뭉치 모음
- CC-100-Kor: CC-100은 CC-NET을 사용하여 대규모 다국어 웹 크롤링 코퍼스를 구축
- 나무위키: 나무위키는 한국어 궵 기반 백과사전으로, 위키백과와 유사하지만 자유로운 형식으로 알려져있음(2020년 3월 2일에 생성된 덤프)
- 뉴스스크롤: 2011년부터 2020년까지 발행한 12,000,000개의 뉴스기사로 구성되어 있으며, 뉴스 집계 플랫폼에서 수집
- 청원: 사회적 이슈에 대한 행정 조치를 요청하는 청와대국민청원 모음. 2017년 8월부터 게시된 청와대 국민청원의 기사들
3. KLUE-TC task
- Topic Classification
- 주어진 뉴스 표제가 어떤 토픽에 속하는지 분류
!pip install -U transformers datasets scipy scikit-learn
import datasets
from datasets import load_dataset, ClassLabel,load_metric
import random
import pandas as pd
from IPython.display import display, HTML
from transformers import AutoTokenizer, pipeline, AutoModelForSequenceClassification, TrainingArguments, Trainer
import numpy as np
import tensorflow as tf
# 이후 코드에서 argmax 함수 사용 가능
model_checkpoint = 'klue/roberta-base'
batch_size = 64
# ['ynat', 'sts', 'nli', 'ner', 're', 'dp', 'mrc', 'wos']
task = 'ynat'
datasets = load_dataset('klue',task)

datasets['train'][:10]
def show_rand_elements(dataset, num_examples = 10):
picks = []
for _ in range(num_examples):
pick = random.randint(0,len(dataset)-1)
while pick in picks:
pick = random.randint(0,len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_rand_elements(datasets['train'])
metric = load_metric('f1')
fake_preds = np.random.randint(0,2,size = (64,))
fake_labels = np.random.randint(0,2,size = (64,))
fake_preds, fake_labels
metric.compute(predictions=fake_preds, references=fake_labels)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast = True)
tokenizer('어버이날 맑다가 흐려져…남부지방 옅은 황사')
print(tokenizer.cls_token_id, tokenizer.eos_token_id)
tokenizer
print(f'Sentence 1: {datasets["train"][0]["title"]}')
def preprocess_function(examples):
return tokenizer(
examples['title'],
truncation=True,
return_token_type_ids=False,
)
preprocess_function(datasets['train'][:5])
encoded_datasets = datasets.map(preprocess_function, batched = True)
num_labels = 7
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint,num_labels=num_labels)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis = 1)
return metric.compute(predictions = predictions, references = labels, average = 'macro')
pip install accelerate -U
metric_name = 'f1'
args = TrainingArguments(
'test-tc',
evaluation_strategy='epoch',
save_strategy='epoch',
learning_rate = 2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size = batch_size,
num_train_epochs = 5,
weight_decay=0.01,
load_best_model_at_end = True,
metric_for_best_model = metric_name
)
trainer = Trainer(
model,
args,
train_dataset=encoded_datasets['train'],
eval_dataset=encoded_datasets['validation'],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
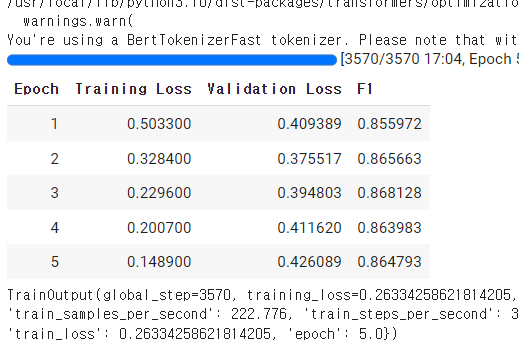
trainer.evaluate()

classifier = pipeline(
'text-classification',
model = './test-tc/checkpoint-1428',
return_all_scores=True
)
classifier('어버이날 맑다가 흐려져…남부지방 옅은 황사')

'''
0 (IT과학)
1 (결제)
2 (사회)
3 (생활문화)
4 (세계)
5 (스포치)
6 (정치)
'''
classifier("차태현 엄마 최수민, '문경' 출연 확정")
